

「データファブリック(Data Fabric)」とは、クラウド、オンプレミス、エッジデバイスなどの様々な場所に存在しているデータを、一元的に利用できるようにするデータ管理のアーキテクチャです。複数の場所に存在する様々なデータの種類やデータソースを接続し、自由にデータへアクセスできるのがあたかも編み物のようなイメージから「ファブリック(織物)」という言葉で表現されます。
仮想化技術でデータの物理的な位置を隠す
データファブリックのアーキテクチャは、いきなり登場したわけではありません。長いデータ活用の歴史を経て登場した最新のアーキテクチャです。ITの進歩に伴ってデータ量が増えるのに合わせてデータ活用の技術も進歩しており、1990年代に「データウエアハウス」、2010年ごろに「データレイク」という手法が登場しました。
データウエアハウスは、デ��ータ活用のための専用データベースを作り、基幹システムなどからデータを取り込みます。取り込み時に目的に沿った形にあらかじめ分類・整理し、特定のツールを使って定型的な分析をしていました。データレイクは収集した生のデータをそのまま格納し、データを利用する際にデータ構造を定義した上で参照・分析します。
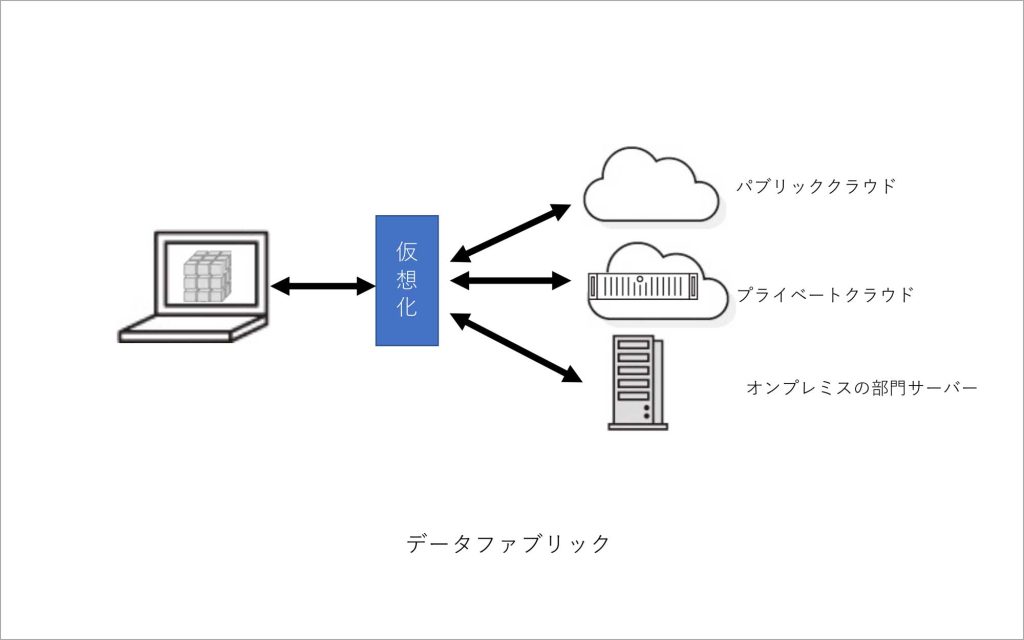
これらに対し、2020年ごろに登場したデータファブリックでは、データを1箇所に集めることはしません。パブリッククラウド、プライベートクラウド、オンプレミスのサーバー、エッジのデバイスといった各データに合ったストレージに格納したまま、標準化した手順でデータを活用できる分散データ基盤を提供します。これを実現する中核技術が“仮想化”です。バラバラに存在するデータを、あたかも一つのストレージにあるかのように仮想化して見せてくれます。
データファブリックを実現すると、データの物理的な位置を意識する必要がなくなり、適材適所で最適な場所にデ��ータを配置したり自由に移動したりできます。頻繁にアクセスするデータはオンサイトに設置した半導体ドライブなどに置き、滅多に利用しないデータは大容量保存用のクラウドなどに退避するように管理するといった、ニーズに合わせたコストの最適化を図ることができます。
データサイロを解消するクラウド接続ストレージとデータファブリック
ビジネス上のニーズやクラウド利用にかかわる政策への対応から、今後数年間でハイブリッドクラウドおよびマルチクラウドの利用が拡大することが見込まれています。また、組織内にデータを大量に保有するだけでなく、分析や活用で新たな知見を見出そうという動きが活発化しています。
しかし自組織がどのようなデータを保有しているか把握し、組織内のデータユーザーが効率的にデータにアクセスできる仕組みを作り上げることは容易ではありません。複数のパブリッククラウドや、オンプレミスのサーバーにデータが散在し、それぞれ独自の運用をされる、データサイロが発生しているのは想像に難くないでしょう。
データサイロは組織内のデータ共有を阻害し、リソースを余計に消費してしまいます。また、整合性の取れていないデータが散在する原因にもなり、分析や活用へのハードルはますます高くなっていきます。データサイロを解消するには、各部門のデータユーザーやアプリケーションからアクセス可能なデータ基盤、つまりクラウド接続ストレージが必要になります。基本的には中央リポジトリとしてのクラウド接続ストレージにデータを集約し、�要件に応じて、必要な場合はオンプレミスや限定的なネットワーク内のストレージも利用を検討します。
代表的なクラウド接続ストレージとして、NeutrixCloudのクラウド接続ストレージがあります。パブリッククラウド(AWS、 Microsoft Azure、GCP)のインスタンスから接続でき、複数のパブリッククラウドから同時にストレージにアクセスすることも可能です。
さらに、機密レベルや用途によってデータを最適な場所に保管し、適切な方法で保護するとともに、すべてのデータの所在を統合的に管理するアーキテクチャ:データファブリックを構築する必要があります。
データファブリックを実現する技術要素
データファブリックは、特定のツールやソリューションではなく、統合的なアーキテクチャであることは既に説明しました。このアーキテクチャを実現するには、様々な技術要素が必要になります。
▽リージョンサイト
・データファブリックを構築すれば、データユーザーはデータの場所を意識することなく、透過的にデータにアクセスできます。その一方で、組織ポリシーや各種規制、基準に準拠するため、データの物理的な保存場所は、管理者が要件に応じて選択できる必要があります。
・要件によっては、遅延を最小化するため、物理的な距離を考慮したデータの配置が求められる場合があります。
▽ストレージ
・パフォーマンスと拡張性に優れ、柔軟な設計が可能なストレージ�が必要不可欠です。
・様々なデータを取り扱うデータファブリックでは、用途に合わせてストレージの種類を選択でき、適正なコストで長期的に維持できることが求められます。
・データの消失や内部や外部の脅威に備え、確実にデータを保護する必要があります。
▽ネットワーク
・データユーザーにデータへのアクセスを提供します。
・要件に応じたパフォーマンスと、適切なセキュリティが担保されたネットワークが求められます。
・アーキテクチャの設計変更やデータの移行に備え、データ転送への制限は最小限であることが望ましいです。
▽コンピュート
・データを収集や活用のためのアプリケーションやサービスを提供する基盤が必要になります。
・高負荷な処理や分析をする場合は、GPUコンピュートの利用を検討します。
進化するデータファブリック
データファブリックは、環境やニーズの変化に応じて構成を変更したり、拡張したりしていくことが求められます。柔軟で拡張性に優れた技術要素を組み合わせることで、強靭で持続可能なデータファブリックを実現することができるでしょう。








